データベース
Squid は複数のデータベースとシームレスに統合できる機能を提供し、データへ簡単にアクセスできるようにします。各データベースは異なる認可(authorization)およびアクセス制御を設定でき、公開したいデータだけにユーザーがアクセスできるようにできます。
Squid の database connectors は、パワフルでシンプルな点が大きな特長です。database connectors を追加すると、整理された SDK を使ってデータにアクセスし、操作できます。
Squid は、無限にカスタマイズ可能なセキュリティ関数、自然言語でデータに対してアドホックな質問ができる Query with AI、さらには別々の database connectors の結果を結合できる細かなデータクエリなど、多くの database 機能を提供します。
データベースへの接続
- Squid Console の Connectors タブに移動します。
- 「Available Connectors」をクリックし、データベースの種類を選択します。
- 必要な接続情報を入力し、接続テストを実行します。
- 「Next」をクリックし、表示される schema が正確であることを確認します。必要に応じて、Squid で使用する予定のないテーブルを削除します(これらは後でいつでも追加し直せます)。
- 「Save」をクリックして connectors を確定します。
Squid's IP address
To prevent denial-of-service attacks, brute force password attacks, and other forms of malicious activity, some providers recommend restricting your network to allow access only from specific IP addresses. This procedure is commonly known as allowlisting, and it limits access to your resources by only accepting connections from a specific list of endpoints.
Refer to your resource provider to determine if you need to add Squid's IP addresses to your access list. If allowlisting is required, you can find Squid's IP addresses on the application overview page of the Squid Console (located in the Cloud Provider section).
Query with AI
Query with AI を使うと、自然言語でデータについて質問できます。Squid AI は、自然言語形式の回答に加えて、回答を得るために実行したデータベースクエリと手順も返します。SQL または NoSQL クエリを書かずにデータを探索したり、アドホックな質問をしたりできます。Query with AI は、データベース connector の Schema タブ、または Squid の AI Agent Studio 内にあります。
Query with AI でできることの詳細は、documentation を参照してください。
接続済みデータベースの使用
クライアントからデータにアクセスするには connector ID を使用します。これは connector 作成時に指定した値です。connector ID は、Squid Console の connectors ページで確認できます。
await squid
.collection('COLLECTION_NAME', 'YOUR_CONNECTOR_ID')
.query()
.eq('field', 'value')
.snapshots()
.subscribe((data) => {
// Do something with your data
});
フルスタックアプリケーションで database connector を操作する方法の詳細は、documentation を参照してください。
データベースの保護
データベース connector を保護するには、database security decorator である @secureDatabase または @secureCollection を使用する関数を 1 つ以上作成します。以下は、バックエンドプロジェクトに追加できる、ユーザーがドキュメント内の userId フィールドを変更できないようにするための、より複雑なセキュリティルールの例です。
export class ExampleService extends SquidService {
@secureCollection('table_name', 'update', 'CONNECTOR_ID')
secureUpdate(context: MutationContext): boolean {
// If the user is not authenticated, the update is not allowed.
const auth = this.getUserAuth();
if (!auth) return false;
// If the userId has changed, the update is not allowed.
const { after, before } = context.beforeAndAfterDocs;
if (after.userId !== before.userId) return false;
// The update is only allowed if the user making the request
// matches the user being updated.
return after.userId !== auth.userId;
}
}
データベース connectors の保護について詳しくは、documentation on securing data を参照してください。
データベース schema
データベースを Squid に接続すると、データベース内の既存のデータ schema に基づいて schema が自動生成されます。schema を表示するには、Squid Console で対象のデータベース connector に移動し、... ボタンをクリックして、ドロップダウンメニューから Schema を選択します。
このインターフェースを使用して、schema 構造の確認、schema の変更、ルールの validation 管理を行い、データの正確性を担保します。
collections と fields の理解
Collections はデータベースにおける主要な整理単位であり、その基盤となる構造は database connector の種類によって異なります。SQL データベースでは collection は table を表し、NoSQL データベースでは collection は documents の collection を表します。
Collections は connector 内で一意の名前によって識別されます。collection は 1 つ以上の document で構成され、SQL データベースでは document は row を表し、NoSQL データベースでは document を表します。document には、異なるデータ要素を示す 1 つ以上の field が含まれます。collection 内の各 field は特定の属性セットによって特徴づけられ、データ管理と connector の利用を効率化します。
以下は、collections と fields の一般的な構造と属性の詳細です。
Collections:
Name: connector 内での一意な識別子で、関連する row または document の集合をグルーピングし参照するのに役立ちます。
Documents:
ID: collection 内での一意な識別子です。ID はランダムにすることもできますが、ユーザー ID やその他の重要なデータポイントにすることもできます。
Fields:
Name: field の名前です。挿入(insert)/更新(update)/クエリ(query)時には、document の field 名と一致している必要があります。Type: field が属するデータカテゴリを指定します。string、number、boolean、date、map、array といった型を含みます。選択した type によっては追加の validation ルールが適用される場合があります。String: 最小/最大長を設定できます。Number: 最小/最大値を設定できます。
Primary Key: field が collection 内の一意な識別子として機能するかどうかを示し、レコードの識別に役立ちます。Required: field へのデータ入力が必須かどうかを示します。Default Value: field にあらかじめ設定された値を割り当てます。
extra fields を許可する
一部の database connectors(多くは NoSQL のデータ構造を持つもの)は dynamic schemas をサポートします。dynamic schema はデータを追加するにつれて変化するため、事前に schema を定義する必要がありません。データの挿入、更新、削除が行われると、データベースが自動的に schema を構築します。dynamic schema がサポートされているかどうかは、使用している database connector の documentation を参照してください。
dynamic schema をサポートする connector では、extra fields はデフォルトで許可されます。collection の schema 変更を防ぐには、Schema に移動し、対象の collection を選択してから Allow extra fields をオフに切り替えます。無効化すると、extra fields を含む document の挿入や更新は拒否されます。
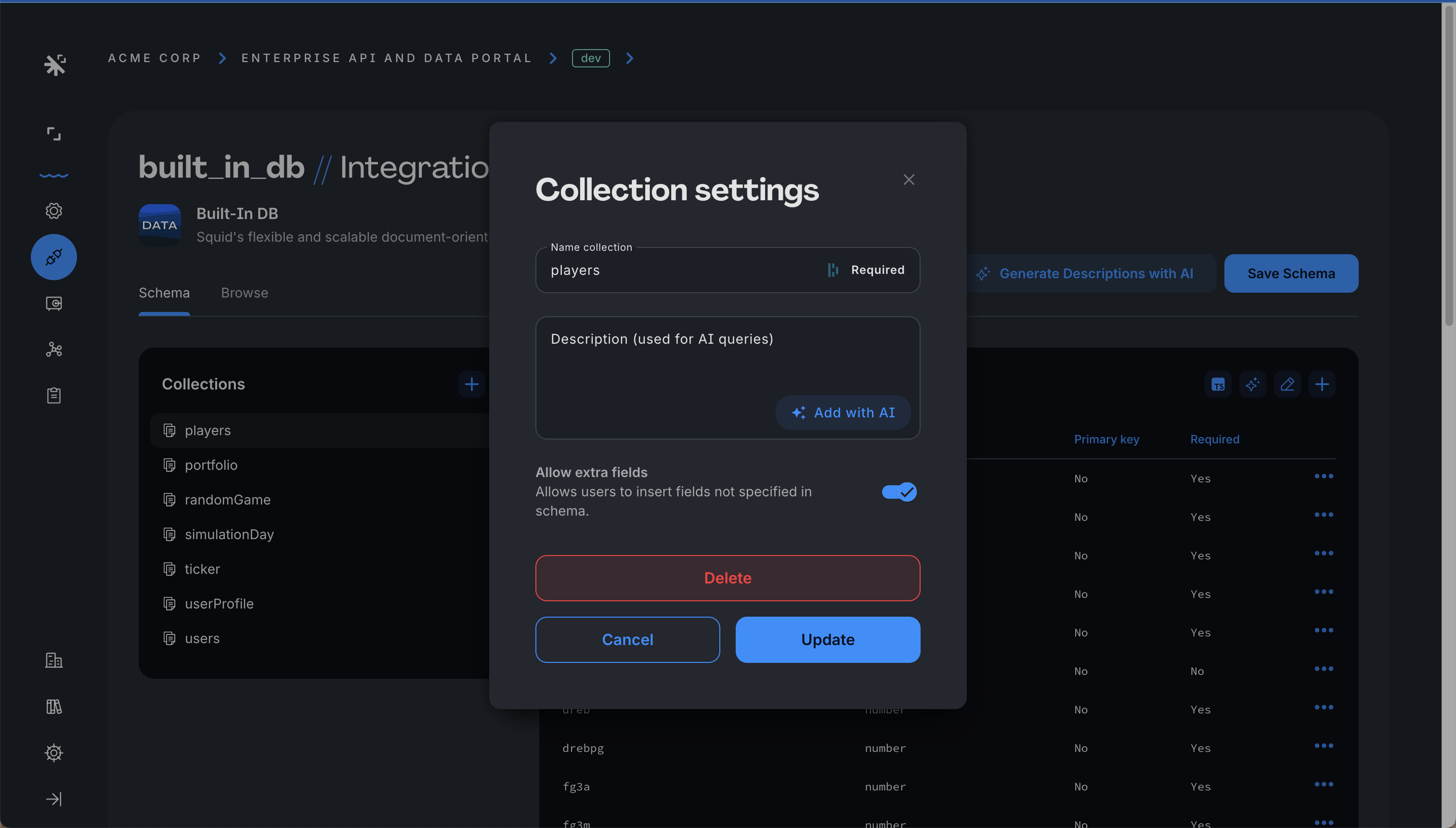
Allow extra fields が無効でも、Rediscover schema をクリックして以前は未知だった field が既知の schema の一部になった場合、その新しい field はシームレスに受け入れられます。